Восстановление видео с камеры Canon LEGRIA HF G30

Восстановление данных с камеры Canon
Обратился к нам клиент с банальной, казалось бы, проблемой – удалил с карты памяти отснятый видеокамерой Canon LEGRIA материал. Большинство сразу скажет: «да воспользуйся любой программой по восстановлению удаленных файлов, в чем проблема?». А проблема, оказывается, есть, и существенная. Все современные камеры, с которыми мы сталкивались – создают на носителе файлы в фрагментированном виде.
Это касается всех камер, сохраняющих видео в формате Apple QuickTime (mov/mp4). Примеры на слуху – зеркальные фотокамеры Canon, экшн-камеры GoPro и их безымянные аналоги, автомобильные видеорегистраторы.
Короткая ремарка по содержимому файлов в указанном формате: файл состоит из сложной вложенной структуры, каждый элемент данных называется атомом. Более подробную информацию можно найти по ссылке, здесь оставлю лишь картинку с обобщённой структурой:
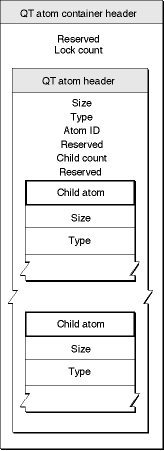
Продолжим. После банального удаления файлов теряется самое важное – информация о расположении фрагментов (кластерная цепочка) файлов. Сразу оговорюсь – ситуация, о которой я говорю, верна для файловой системы FAT32. Для NTFS или ExFAT ситуация может быть другой. И в случае с FAT32 и удалёнными фрагментированными файлами существует всего два метода их восстановления:
- Поиск и анализ на носителе непосредственно видеопотока и воссоздание для него необходимых служебных метаданных, и
- Анализ служебных метаданных видеофайлов и сборка фрагментов вручную по найденным зацепкам.
Мы уже неоднократно работали с разными видеоформатами, и знаем, что далеко не каждый поток видео/аудио данных можно восстановить и воспроизвести без сопроводительных служебных метаданных. Например, простой формат MPEG-2 – является потоковым, и для его воспроизведения не нужны никакие дополнительные служебные данные – просто сырой поток данных, выровнянный по границе фрейма.
Такой поток можно восстановить первым методом и не тратить время на служебные данные. Также первым методом можно восстанавливать сырой видеопоток без служебных данных, даже если он был в Apple QuickTime контейнере (mov/mp4), при условии использования определенного видеокодека. Однако данная видеокамера создает файлы с видеопотоком, который не оставляет шансов на восстановление первым методом:

В таком формате нет никаких «зацепок», чтобы отделить фреймы с видео и аудио данными друг от друга. Они идут сплошным потоком, а информация о том, где находятся границы фреймов – сохранена в служебных атомах trak. Эти метаданные записываются камерой в виде отдельного фрагмента в отдаленном от основного потока данных месте носителя.
Причём как показали наши исследования, каждая камера записывает на носитель фрагменты видео по-разному, везде используется разный алгоритм их размещения. Где-то этот алгоритм прост, и его можно воспроизвести, получив на выходе полностью дефрагментированные, рабочие видеофайлы (зеркалки Canon). В случае с подопытной видеокамерой – никакой особой закономерности нет – камера просто пишет метаданные в одну часть носителя, а видеопоток – в другую. При этом метаданные могут дополнительно фрагментироваться. В общем, всё плохо, и задача на первый взгляд выглядела нерешаемой.
Однако, изучив в HEX-редакторе несколько примеров видеофайла с подопытной камеры, был придуман алгоритм сборки «фрагментов» по маркерам из содержимого файла. Для решения задачи необходимо полностью проанализировать пример файла, понять какие атомы используются, какую информацию из них мы можем использовать, и как затем, находя содержимое этих атомов на носителе, соединить найденные фрагменты в единое целое. Для понимания первичной структуры используем MP4 Explorer:
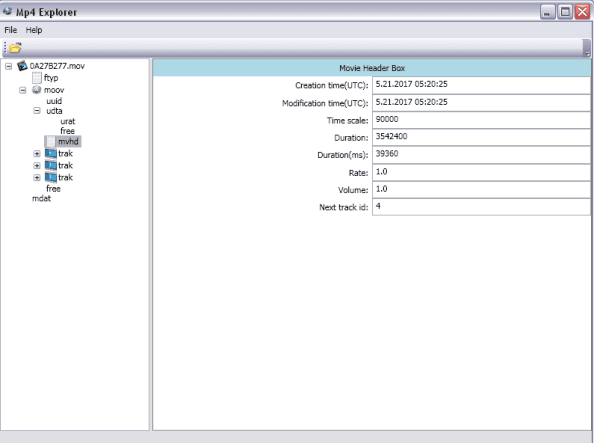
Структура стандартная. Атом mvhd с временем создания файла оказался для нас очень важным – по времени создания можно связать найденный на диске фрагмент с атомами trak с началом файла, фрагментом ftyp. Глянем на начало файла в HEX виде:
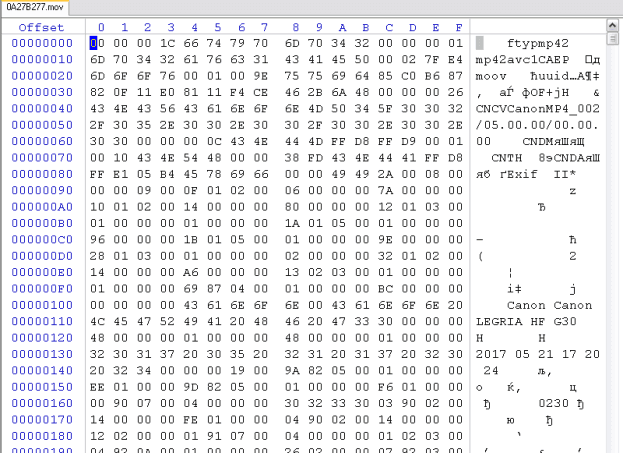
Здесь в служебном атоме CNTH->CNDA находится картинка-превью файла, в которой очень удачно для нас есть дата создания файла в текстовом виде. Эта информация очень пригодится далее. Как оказалось, камера при формировании метаданных резервирует фиксированное место под превью-картинку, а также для пользовательской информации, которую можно поместить в служебный атом udta. Ну а самое главное, что атом с непосредсвенно медиапотоком, mdat – записывается камерой нефрагментированно. И снова очень удачно – в этом атоме есть за что зацепиться для поиска соответсвующего ему атома mhvd и ftyp.
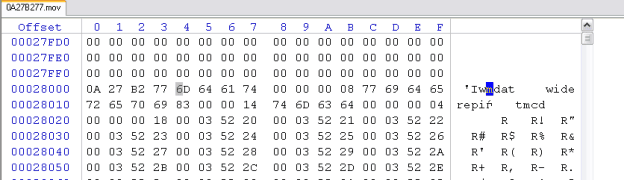
Приступаем к созданию инструмента для восстановления - создаем новый проект в С++ Builder:
Первый же проход свежесозданным анализатором по носителю показал, что шансы на успех неплохие, но впереди много работы.
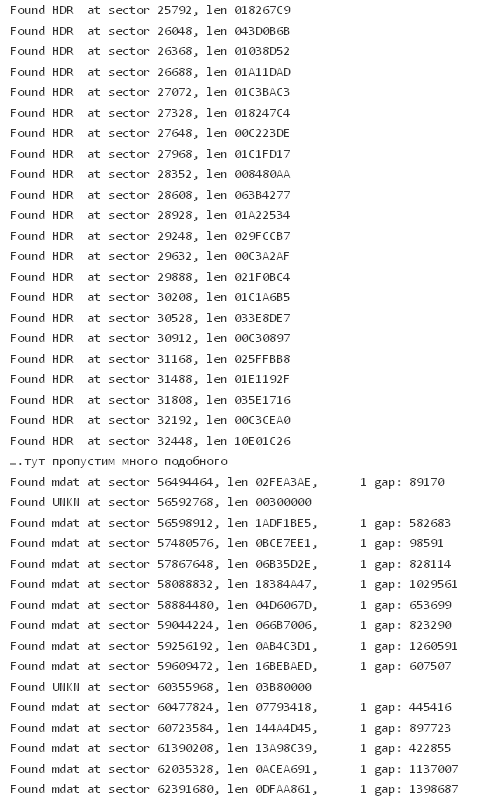
По ходу написания инструмента придумываем алгоритмы валидации целостности найденных фрагментов, как оказалось - это реально. Нашлось заголовков файлов и секций mdat с видеопотоком:
После – обрабатываем массив найденных данных, анализируем те атомы, которые можем, и даже проверяем на нефрагментированность найденные контейнеры.
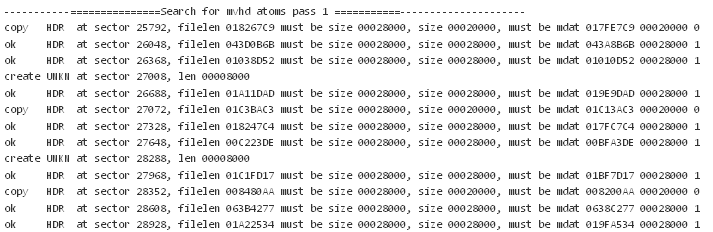
Неплохо, часть метаданных нашлась единым фрагментом, но есть и фрагментированные. С ними будем разбираться позже. Далее связываем найденные фрагменты с метаданными с соответствующими им атомами mdat и сохраняем полученные видеофайлы, попутно проверяя их содержимое отдельной функцией-валидатором структуры атомов:
FILE 043A8B6B.mov check ok!
FILE 01010D52.mov check ok!
FILE 019E9DAD.mov check ok!
FILE 017FC7C4.mov check ok!
FILE 00BFA3DE.mov check ok!
Проверим файлы:
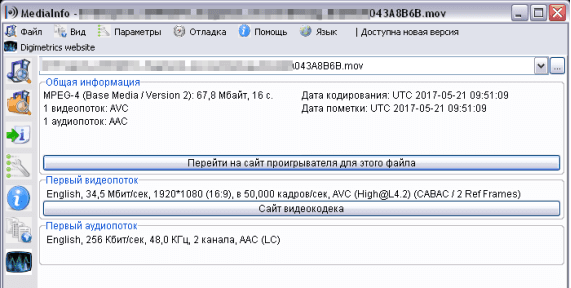
Все проигрывается! Ура, но еще осталось около 20% невосстановленных файлов, метаданные которых оказались фрагментированы. Пишем для них отдельный сборщик, который свяжет найденные фрагменты начала и середины метаданных, опираясь на дату создания файла:
В итоге получилось еще часть рабочих файлов.
На данном этапе осталось всего 25 фрагментов с метаданными, которые не удалось собрать в целостные файлы. Сохраняем все оставшиеся фрагменты в виде отдельных файлов, и собираем оставшиеся файлы вручную, опираясь на знания о том, что где должно лежать внутри файла. Как оказалось, метаданные этих 25 файлов были сильно фрагментированы – от 3 до 5 фрагментов. Однако через несколько часов кропотливой работы все до единого файлы удалось собрать.
Как результат, мы получили ровно 244 рабочих файла, что является 100% успешным восстановлением (чуть выше в логе видно количество найденных заголовков файлов – их было 244).
Клиент остался очень доволен, ведь свадьбу переснять уже невозможно...

Відправити відповідь
Залиште перший коментар